Needle: A DFA Based Regex Library that Compiles to JVM ByteCode
Many years ago, Kragen complained about the implementation and performance of Java regexes, and suggested that an implementation that emitted JVM bytecode could perform better. It's been a minute, but I'm happy to report that complaining on the Internet has served its purpose.
Today, I'm releasing the 0.0.1 version of needle, a library
that compiles regular expressions to JVM bytecode. It
compiles each regular expression to a Deterministic Finite
Automaton (DFA), which is then compiled to a Java class. The
code analyzes the DFA to extract information that helps match
more efficiently. It detects required prefixes, suffixes and
infixes that can be found using String.indexOf,
as well as cases where the first character can be easily
tested in a while loop (e.g. [Ss]). This lets
the class spend less time inside the DFA automaton, and more
in a fast loop.
Benchmarks
Regex performance resists concise summarization, and the design of needle makes this even more true. For instance, one optimization computes the minimum and maximum length of a match, and uses that to bail out early when a match is not possible. This effect will show up when testing that an entire string matches a regex, or when searching in a sufficiently small string, but won't show up when finding substrings that match inside of a large string.
I've written a number of benchmarks, covering many different cases, but need to write code to repeatably report and compare results. In the meantime, I've included partial results for one specific benchmark (SherlockBenchmark).
For each regex, we search the Project Gutenberg edition of The Adventures of Sherlock Holmes, finding all matches for the pattern. For each regex, we compare the Java standard library, Needle, and the brics automaton library, which is an efficient DFA implementation.
There are three categories of patterns in the test:
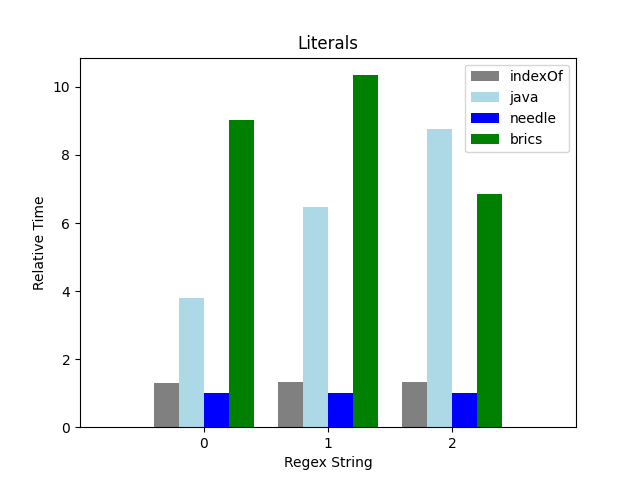
Literals
These patterns have no repetition or meta-characters, and
could be found using String.indexOf. Needle
recognizes the literal, and includes a call to
String.indexOf. The standard library is still
significantly slower, but does surprisingly well on
these.
Of course, doing well on these strings is not necessarily
that interesting--unless there's a level of indirection, you
could just replace the regex use with a
String.indexOf.
SherlockAdlerzqjaqjlet us hear a true
These results include the time it takes to use
String.indexOf in a loop. Subsequent graphs
don't, because it no longer makes sense as a comparison.
Update: looking at this again, it's odd that needle is
outperforming indexOf. The numbers are similar enough, which is
to be expected, but I don't have an explanation for them being
better. I'll have to investigate further, and potentially
correct these numbers.
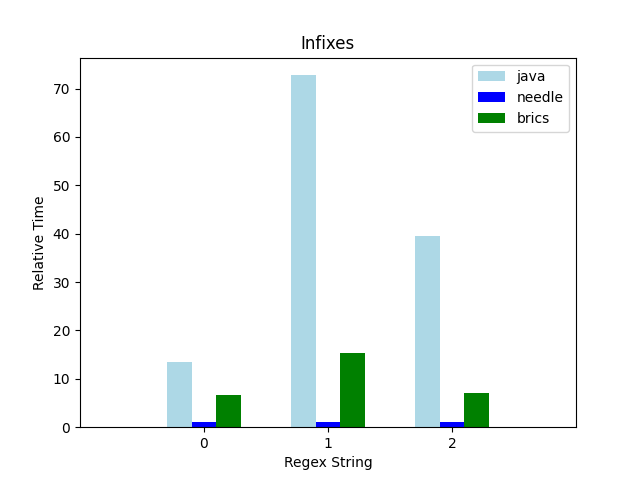
Substring/Initial Character Searches
These patterns are not literals, but have literal
components that let us narrow the search space by using
String.indexOf.
[Ss]herlockanywhere|somewhere-
Holmes.{0,25}Watson|Watson.{0,25}Holmes the\s\w{1,20}\s\agencySherlock\s\w{1,20}edSherlock|Streetthe\s+\w+[a-zA-Z]+ing\s[a-zA-Z]{0,12}ing\s[a-z][a-e]{6}z
Everything Else
These patterns have no substring to search for using
String.indexOf so the matching is done entirely
by the automaton.
Sherlock|Holmes-
Sherlock|Holmes|Watson|Irene|Adler|John|Baker ([Ss]herlock)|([Hh]olmes)Adler|Watson

Needle is slower than brics on these patterns, but still much faster than the standard library. This is because the core loop of the needle automaton is slower than the brics automaton. When we have a usable substring for searching, the performance of the regex is dominated by the speed of searching for that substring, and the automata speed is less important. But when there is no substring, brics wins.
There are two things that I'd like to do here. First, we can probably expand the cases where we do a fast loop searching for the initial character of our regex (or extend the search to non-initial characters). Looking at the cases above, we have various facts about the initial character (it must be uppercase, it's one of four characters, etc). Some of these predicates should allow us to emit a call that efficiently checks if they're true.
Second, for the remaining regexes, that do not allow using a fast initial loop, I'll have to change the generated code to match or exceed the performance of brics. I don't have a plan, but structurally, it has to be possible. Since we can compile each regex to an independent set of code, we could in principle just output a loop with the same structure as the brics automaton. It's unlikely that's the best approach, but it implies that there's no structural reason needle couldn't match any competitor's performance. The only constraint is how much complexity we can handle in compiling different regexes.